Билет № 18
1.
Алгоритмы быстрого
преобразования Фурье. Требования, предъявляемые к сигнальному процессору.
БЫСТРОЕ ПРЕОБРАЗОВАНИЕ ФУРЬЕ
Много усилий было затрачено на разработку более
эффективных путей вычисления ДПФ. Эти усилия привели к эффективным в
вычислительном отношении алгоритмам, которые все вместе известны как алгоритмы
быстрого преобразования Фурье (БПФ). Ускорение расчётов по алгоритму БПФ
достигается за счёт чисто алгоритмических и организационных средств путём
исключения повторных вычислительных операций, характерных для расчётов по
формулам ДПФ:
Используется свойство периодичности ядра преобразования 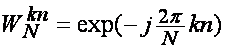 .
.
Используется значение N=2 в степени
(или 4 в степени) и неоднократное прореживание
отсчётов (децимации) по времени или по частоте.
Алгоритм БПФ выполняется рекурсивно за ![]() этапов. Расчет для
N/2 выполняется после расчёта для N/4 и т. д.…
этапов. Расчет для
N/2 выполняется после расчёта для N/4 и т. д.…
Быстрое преобразование Фурье (FFT)
требует только (N/2)log2(N)
умножений комплексных чисел. Вычислительная эффективность БПФ по сравнению с
ДПФ становится весьма существенной, когда количество точек БПФ увеличивается до
нескольких тысяч. БПФ вычисляет все компоненты выходного спектра (или все, или
ни одного!). Если необходимо рассчитать только несколько точек спектра, ДПФ
может оказаться более эффективным. Вычисление одного выходного отсчета спектра
с использованием ДПФ требует только N умножений комплексных чисел.
Архитектура и набор инструкций процессора
ADSP-21xx очень удобны для выполнения алгоритмов БПФ. Эти алгоритмы
неоднократно исполняют операцию умножения/накопления при выборочном
использовании входных данных. Это требует очень эффективной генерации адресов,
которая обеспечивается двумя генераторами адресов данных (DAG0 и DAG1). Кроме
того, DAG1 имеет аппаратные средства для реверса битов, используемые при
сортировке отсчётов.
2.
Интерфейс с памятью
данных. Карта памяти данных.
В процессоре ADSP-21XX
предусмотрены средства для обращения к внутренней и внешней памяти данных общим
объемом 16K 16-битовых слов. При обращении к внешней памяти данных
используются:
-вывод DMS процессора, на который выставляется
строб DMS == 0 для активизации памяти данных; -выходы
RD/WR процессора для чтения/записи памяти
данных; -14-битовая внешняя шина адреса (ВША) для адресации;
-24-бшовая внешняя шина данных (ВШД) для вывода
16 старших бит данных.
При обращении к внутренней памяти данных сигналы
PMS, DMS, RD, WR
имеют высокий уровень, исключающий возможность активизации микросхем внешней
памяти, а внешние шины адреса и данных переходят в высокоомное
состояние.
3. Периферийные
устройства, расположенные на кристалле ЦСП. Их назначение.
Устройство памяти процессора включает раздельную
память программ (РМ) типа ОЗУ или ПЗУ, где могут храниться также и
данные, и память данных (DM) типа ОЗУ.
Внутренние устройства процессора связаны
14-разрядными шинами адреса памяти данных DMA (Data
Memory Address) и адреса памяти
программ РМА (Program Memory
Address), 16-разрядной шиной данных памяти данных DMD (Data
Memory Data) и 24-разрядной шиной
данных памяти программ PMD (Program
Memory Data). Они
мультиплексированы в две выводимые наружу внешние шины, шину адреса и шину
данных. По шине внутренних результатов R осуществляется прямой
обмен данными между вычислительными устройствами.
Память и шины адресов и данных. Семейство ADSP-21xx
использует модифицированную гарвардскую архитектуру, в которой память данных (Data Memory) хранит данные, а
память программ (Program Memory)
хранит как программный код, так и данные. Процессоры семейства также имеют
отдельные адресные пространства байтовой памяти (Byte Memory)
и памяти устройств ввода-вывода (I/O Memory). Все процессоры
семейства содержат встроенное статическое ОЗУ, разделенное на память программ и
память данных. Быстродействие встроенной памяти позволяет процессору в течение
одного цикла считать 2 операнда (по одному из памяти данных и памяти программ)
и 1 команду из памяти программ.
Эффективная пересылка данных достигается путем
использования пяти внутренних шин:
шина
адреса
памяти
программ (Program Memory Address Bus – PMA Bus);
шина
данных
памяти
программ (Program Memory Data Bus – PMD Bus);
шина
адреса
памяти
данных (Data Memory Address Bus – DMA Bus);
шина
данных
памяти
данных (Data Memory Data Bus – DMD Bus);
шина внутреннего результата (R Bus).
Две шины адреса (PMA и DMA)
мультиплексированы в единую внешнюю шину адреса, шины данных (PMD
и DMD) мультиплексированы в единую внешнюю шину данных. Это позволяет
подключать дополнительную внешнюю память как данных,
так и программ. Эти же внешние шины адреса и данных используются при обращении
к памяти устройств ввода/вывода и байтовой памяти.
Устройство обмена данными между шинами PMD
- DMD аппаратно поддерживает двунаправленную передачу данных
между памятью программ и вычислительными устройствами процессора.
Два двунаправленных последовательных
порта (SPORT) с широким разнообразием аппаратно-реализуемых
режимов передачи и приема данных обеспечивают полный синхронный
последовательный интерфейс процессора.
Два независимых последовательных порта
(Serial port – SPORT) обеспечивают
последовательный интерфейс с аппаратурой сжатия/восстановления данных, а также
с большим кругом стандартных устройств. Порты могут работать от внутреннего
таймера или тактироваться извне (частота синхронизации порта может составлять
до ½ тактовой частоты процессора). Порты дуплексные, синхронные (могут
работать в асинхронном режиме), имеют сигналы синхронизации кадра, формируемые
извне или самостоятельно. Длина пересылаемых слов от 3 до 16 бит.
Поддерживается режим аппаратного компандирования по
А-закону и -закону. Возможны
передача и прием данных из кольцевого буфера с помощью генераторов адресов
данных (автобуферизация). Приемник и
передатчик каждого порта генерирует прерывание по завершении пересылки
отдельного слова или содержимого всего буфера (при автобуферизации).
Каждый последовательный порт имеет 5 внешних сигналов (SCLK – тактовый
синхросигнал; RFS – синхронизация приема кадра; TFS – синхронизация передачи
кадра; DR – принимаемые последовательные данные; DT –
передаваемые последовательные данные).
Программируемый интервальный таймер выполняет
периодическую генерацию внутренних прерываний.
Таймер (Timer)
– программируемый 16-разрядный таймер/счетчик с 8-разрядным предварительным
делителем обеспечивает возможность генерации периодических прерываний с широким
диапазоном периодов.
Таймер включает в себя: два 16-разрядных регистра – TCOUNT и TPERIOD, и один
8-разрядный – TSCALE. Возможно разрешение и запрещение
работы таймера установкой и очисткой бита 5 в регистре MSTAT.
TSCALE содержит коэффициент, на который делится тактовая частота процессора
перед подачей на вход таймера. TCOUNT – регистр-счетчик. Если таймер разрешен,
он декрементируется по приходу каждого импульса синхронизации. Когда счетчик
достигает нуля, генерируется прерывание. Затем в регистр TCOUNT загружается
значение, находящееся в регистре TPERIOD и счет продолжается снова.
Параллельный интерфейс представлен портами
прямого доступа к памяти BDMA и IDМА.
Контроллер прямого доступа к байтовой памяти
(BDMA – Byte Memory DMA) обеспечивает загрузку
и сохранение команд и данных, используя пространство байтовой памяти.