Билет № 20
1. Передаточная (системная) функция дискретной цепи. Схема дискретной цепи.
Из формулы 2.1 следуют схема дискретной цепи общего вида и схема алгоритма вычислений:
|
|
|
|
|
|
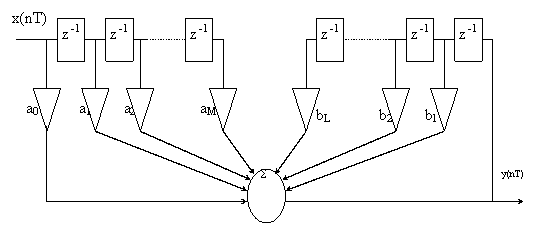
Хорошо прослеживается взаимосвязь выражения (2.1) и возможных путей прохождения сигнала в схеме. Дискретная цепь, содержащая обратную связь, называется рекурсивной.
Рекурсия – математический приём, состоящий в циклическом обращении к данным, полученным на предшествующих этапах. Для формирования i-го выходного отсчёта используются предыдущие значения не только входного, но и выходного сигнала:
Левая часть схемы является нерекурсивной (трансверсальной) частью алгоритма. В ней m ячеек, сохраняющих входные отсчёты. Правая, рекурсивная часть алгоритма использует n выходных значений, которые перемещаются из ячейки в ячейку
Недостатком прямой формы рекурсивной дискретной цепи является потребность в большом числе ячеек памяти, отдельно для рекурсивной и нерекурсивной её частей.
Передаточная функция
Замена сигналов в разностном уравнении (2.1) на z-изображения этих сигналов и учёт свойств линейности и запаздывания приводит к алгебраической форме разностного уравнения:
![]() (2.2)
(2.2)
Передаточная (системная) функция дискретной цепи H(z) определяется как отношение z-изображений сигналов на выходе Y(z) и входе X(z) дискретной цепи:
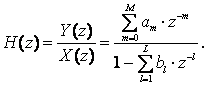 (2.3)
(2.3)
Варианты соединения звеньев дискретной цепи
Каскадное соединение – наиболее употребительно.
 H(z) = H1(z) ·H2(z) ·H3(z)
H(z) = H1(z) ·H2(z) ·H3(z)
Параллельное соединение – потребуется не один процессор.
|
|
|
|
|
|
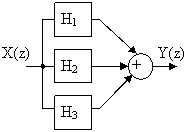
H(z) = H1(z) +H2(z) +H3(z)![]()
Включение цепи H2(z) в обратную связь цепи H1(z):
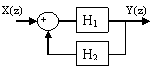
![]()
![]()
Основы реализации
Схему цепи по дробной передаточной функции H(z) удобно строить в 2 этапа: сначала нерекурсивная часть, соответствующая числителю, затем каскадно с ней - рекурсивная часть, соответствующая дроби, числитель которой равен единице.
Основой каскадной реализации является представление функции H(z) в виде произведения простейших сомножителей в числителе и знаменателе
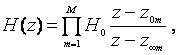 (7.1)
(7.1)
где z0m – нули H(z), zm – полюсы H(z).
Сомножителям 1-го порядка (нули и полюсы - вещественные) соответствуют звенья 1-го порядка. Сомножителям 2-го порядка (нули и полюсы – комплексно-сопряженные) соответствуют звенья 2-го порядка.
Каскадный принцип реализации передаточной функции высокого порядка приводит к снижению уровня шумов квантования.
Критерий физической реализуемости и устойчивости дискретной цепи совпадает с критерием для аналоговой цепи и состоит в удовлетворении требований:
коэффициенты a M и bL – вещественные числа,
корни знаменателя, то есть полюса H(z), расположены в пределах единичного круга плоскости z.
Дискретная цепь может осуществлять любые операции: фильтрацию сигнала, корректирование характеристик и т. п., то есть выполнять функции любой аналоговой цепи.
Наиболее изученный и внедрённый класс систем цифровой обработки сигналов – так наз. цифровые фильтры. Их преимущества по сравнения с аналоговыми фильтрами: высокая стабильность параметров, не требуют настройки, реализация в виде программ для ЭВМ. Появление микропроцессоров и полупроводниковой памяти дало новый стимул для развития цифровой фильтрации.
2. Особенности использования и программирования линейного буфера.
Режим адресации линейного или циклического буферов для используемого индексного регистра I задается регистром длины буфера L, имеющим с регистром I одинаковый номер, т.
е. I0-L0, I1 -L1 и т. д.
При инициализации регистра L отличным от нуля значением активизируется устройство адресации по модулю, обеспечивающее автоматическую адресацию циклического буфера длиной, определяемой значением регистра L.
Линейная адресация обеспечивается при записи в регистр L нулевого значения длины кольцевого буфера, блокирующего устройство модульной адресации.
После перезапуска процессора в регистрах I, M и L содержатся случайные значения. Поэтому программа должна обязательно предусматривать инициализацию регистров L, соответствующих всем используемым регистрам I.
Ниже приводимая последовательность инструкций является простым примером задания и использования линейной косвенной адресации:
I3=0x3800; M2=1; L3=0; I7=0x0100; M4=1; L7=0;
МX0=DM (I3, M2); МX1=PM (I7, M4); MR=MX0*MX1;
В случае циклической или модульной адресации следующий адрес циклического (кольцевого) буфера вычисляется в соответствии с выражением:Следующий адрес = (I+M - B) по модулю (L) + B,
где I - это текущий адрес; M - модифицирующее значение (со знаком); В - базовый адрес; L - длина буфера, отвечающая условию: L>|M|.
Вычисленный адрес записывается в индексный регистр I и становится текущим адресом ячейки памяти.
Базовый адрес циклического буфера длины L равен 2n или кратен 2n , где n удовлетворяет условию: 2n-1 < L < 2n. На практике не требуется самим вычислять n; редактор связей автоматически помещает циклический буфер по правильному адресу.
Приводимый пример иллюстрирует вычисление адреса при модульной адресации:
Пусть I0 = 4, M0 = 1 , L0 = 3, базовый адрес B = 4. Следующий адрес = (4+1-4) по модулю (3) + 4 = 5; Следующий адрес = (5+1-4) по модулю (3) + 4 = 6; Следующий адрес = (6+1 -4) по модулю (3) + 4 = 4 и т. д.
Модульная адресация данных применяется, как правило, в циклах, организуемых с помощью инструкции DO UNTIL. Ниже приведен простой пример инициализации и исполнения такого цикла:
3. Гарвардская архитектура и её достоинства.
Основной особенностью гарвардской архитектуры является использование раздельных адресных пространств для хранения команд и данных, как показано на
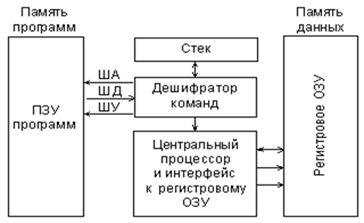
Рис. 4.3. Структура МПС с гарвардской архитектурой.
Гарвардская архитектура почти не использовалась до конца 70-х годов, пока производители МК не поняли, что она дает определенные преимущества разработчикам автономных систем управления.
Дело в том, что, судя по опыту использования МПС для управления различными объектами, для реализации большинства алгоритмов управления такие преимущества фон-неймановской архитектуры как гибкость и универсальность не имеют большого значения. Анализ реальных программ управления показал, что необходимый объем памяти данных МК, используемый для хранения промежуточных результатов, как правило, на порядок меньше требуемого объема памяти программ. В этих условиях использование единого адресного пространства приводило к увеличению формата команд за счет увеличения числа разрядов для адресации операндов. Применение отдельной небольшой по объему памяти данных способствовало сокращению длины команд и ускорению поиска информации в памяти данных.
Кроме того, гарвардская архитектура обеспечивает потенциально более высокую скорость выполнения программы по сравнению с фон-неймановской за счет возможности реализации параллельных операций. Выборка следующей команды может происходить одновременно с выполнением предыдущей, и нет необходимости останавливать процессор на время выборки команды. Этот метод реализации операций позволяет обеспечивать выполнение различных команд за одинаковое число тактов, что дает возможность более просто определить время выполнения циклов и критичных участков программы.
Большинство производителей современных 8-разрядных МК используют гарвардскую архитектуру. Однако гарвардская архитектура является недостаточно гибкой для реализации некоторых программных процедур. Поэтому сравнение МК, выполненных по разным архитектурам, следует проводить применительно к конкретному приложению.